




Hey folks! 👋
Not so long ago, I came across a post from LangChain on the Threads App about how easy it is to create a chat assistant using Llama2.

Here's the tutorial that you can look into, thanks to Anil-matcha who shared it on GitHub.
I've been fascinated by how difficult it generally is to physically host an LLM, but first, let's create an app.
Creating a working environment on Napptive
I sneaked into the documentation a bit and found out that the model can work just on the CPU, but it does better if you also have a GPU.
Since this is all Python, we can create the app on a Jupyter environment as well. The easiest way to create a Jupyter environment on the cloud is by using Napptive.
To learn more about Napptive and an extensive guide on hosting your Jupyter Lab on Napptive, here's one of my old articles you can refer to.
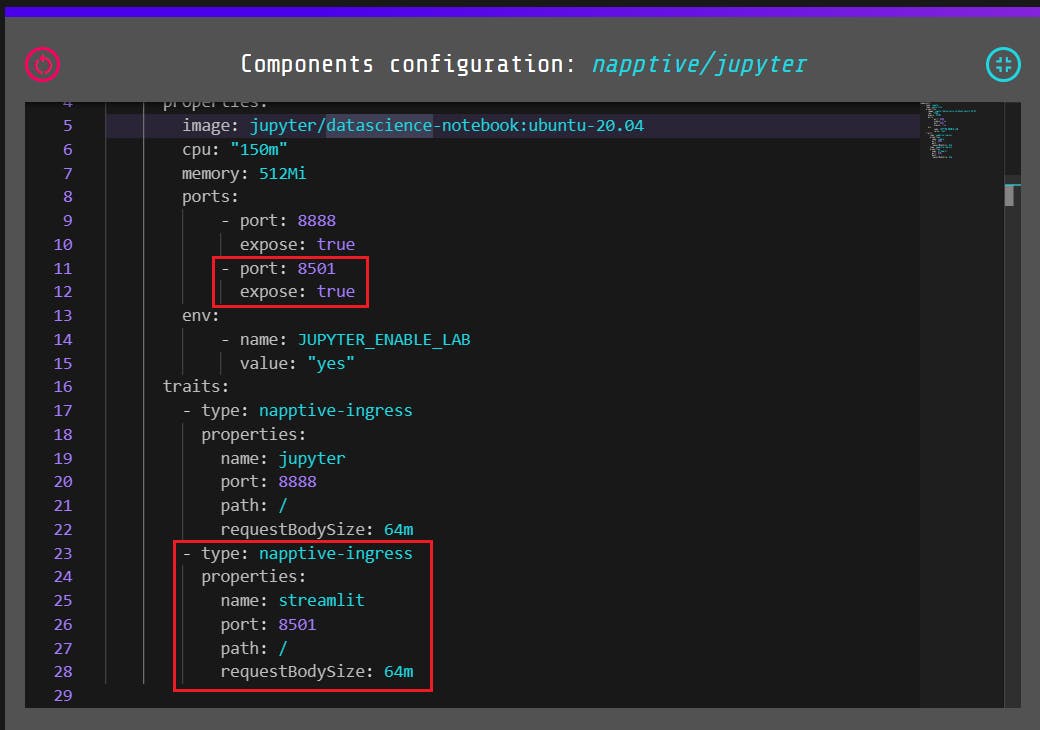
Before you deploy the app though, you'll have to make a couple of changes to the config YAML file. Firstly, expose the port 8501 for streamlit and create a napptive-ingress trait for it. This is because we'll be using Streamlit for the app UI.
Once that's done, you can deploy the app.
Building the App
Once you get into the Jupyter environment, create a new terminal, we have a few things to set up before we get going.
# Install langchain, the llama module and streamlit
pip install langchain llama-cpp-python streamlit
# Download Llama2 model from hugging-face
wget https://huggingface.co/TheBloke/Llama-2-13B-chat-GGML/resolve/main/llama-2-13b-chat.ggmlv3.q4_0.bin
mkdir .streamlit
nano .streamlit/config.toml
## Add this to the config
[theme]
primaryColor="#F63366"
backgroundColor="#111827"
secondaryBackgroundColor="#6B7280"
textColor="#FFFFFF"
font="sans serif"
## Ctrl + S to save the file, Ctrl + X to exit
The UI for this is inspired by the Streamlit ChatBot tutorial which you can find here.
Once the config is setup, create a new file app.py
import streamlit as st
# App title
st.set_page_config(page_title="💬 LLama2 Langchain ChatBot")
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I help you?"}]
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
Initially, we'll just import streamlit, setup an array to store all chat messages in a streamlit-session and then create the UI for the chat.
from langchain.llms import LlamaCpp
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain import LLMChain, PromptTemplate
from langchain.memory import ConversationBufferWindowMemory
We'll import all the different classes and functions we'll use from Langchain.
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# Make sure the model path is correct for your system!
llm = LlamaCpp(
model_path="./llama-2-13b-chat.ggmlv3.q4_0.bin",
input={"temperature": 0.75, "max_length": 2000, "top_p": 1},
callback_manager=callback_manager,
verbose=True,
)
# Function for generating LLM response
def generate_response(prompt_input):
template = """I am a Large Language Model Llama set up on Langchain.
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(input_variables=["history", "human_input"], template=template)
chatbot = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=ConversationBufferWindowMemory(k=2),
)
return chatbot.predict(human_input=prompt_input)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner():
response = generate_response(prompt)
st.write(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
Further, we initialize the LLM Class with the model that we downloaded, write a function that creates the chain to generate responses and lastly, the UI to showcase those responses.
Refer to the snippet below for the entire code from the file app.py
import streamlit as st
from langchain.llms import LlamaCpp
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain import LLMChain, PromptTemplate
from langchain.memory import ConversationBufferWindowMemory
# App title
st.set_page_config(page_title="💬 LLama2 Langchain ChatBot")
# Store LLM generated responses
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": "How may I help you?"}]
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# Make sure the model path is correct for your system!
llm = LlamaCpp(
model_path="./llama-2-13b-chat.ggmlv3.q4_0.bin",
input={"temperature": 0.75, "max_length": 2000, "top_p": 1},
callback_manager=callback_manager,
verbose=True,
)
# Function for generating LLM response
def generate_response(prompt_input):
template = """I am a Large Language Model Llama set up on Langchain.
{history}
Human: {human_input}
Assistant:"""
prompt = PromptTemplate(input_variables=["history", "human_input"], template=template)
chatbot = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=ConversationBufferWindowMemory(k=2),
)
return chatbot.predict(human_input=prompt_input)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner():
response = generate_response(prompt)
st.write(response)
message = {"role": "assistant", "content": response}
st.session_state.messages.append(message)
Running the App
To run this file, create a new Terminal window and run the following command -
streamlit run app.py
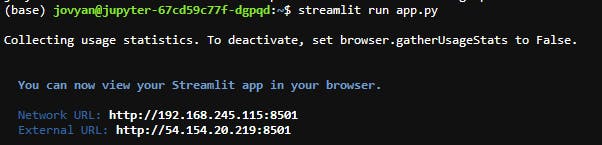
If the service is up and running, you'll see a similar message in the shell from Streamlit.
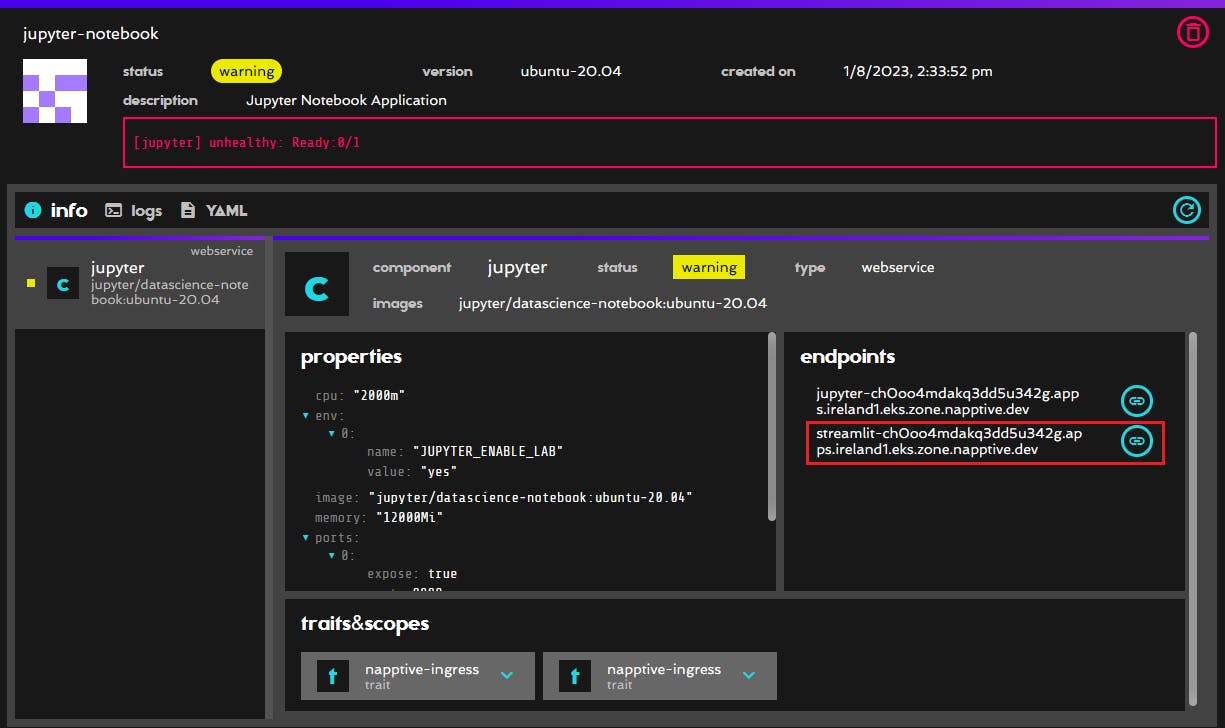
You can check the app following the link in the streamlit endpoint on the Napptive Console.

While you enter the prompts on Chat, you can also check out what it does on the Terminal.
Final Results

Here's a demo of what the app looks like.
The app runs fine, but I've come across a few issues, for starters it's very slow (understandably because it's on CPU) and secondly, sometimes it loops itself where after finishing the response it automatically creates a new question and starts answering it.
What could've been better?
I didn't spend too much time on the UI, so you can see that the chatbot just dumps the response instead of streaming it word-by-word as you would see on other bots like ChatGPT.
That's it for this article, I hope you liked it, stay tuned on this series because I'm pretty sure there's a lot more to come. In the next article, we'll try something similar with the help of AWS Sagemaker :)
As always, thanks for reading, keep spreading your love, Cheers! 🥂